本文将先介绍PyTorch dispatcher实现原理,然后再浅析v2.7.1版实现源码,希望能对大家有所帮助。 在继续阅读下文之前,建议先阅读PyTorch核心开发者Edward Z. Yang的Let’s talk about the PyTorch dispatcher以对dispatcher核心原理有所认识, 本文原理部分也主要参考了这篇文章。
1. Dispatcher问题背景与实现原理
PyTorch目前可以在CPU/CUDA/FPGA等多种后端设备上支持上千个算子,并且随着时间发展,PyTorch还需要不断支持新设备和新算子。 因此,PyTorch在代码架构设计上需要具有极强的可扩展性,而这目前是通过dispatcher来实现的。 Dispatcher在PyTorch代码架构中具有核心的作用,用Edward Z. Yang的话来说就是it is a really important abstraction for how we structure our code internally.
Dispatcher要解决的需要同时支持新设备和算子的扩展问题在本质上是expression problem, 目前其并没有较好的通用解法。 例如,在编译器领域,该问题为如何高效地给下图所示的表同时新增行和列。
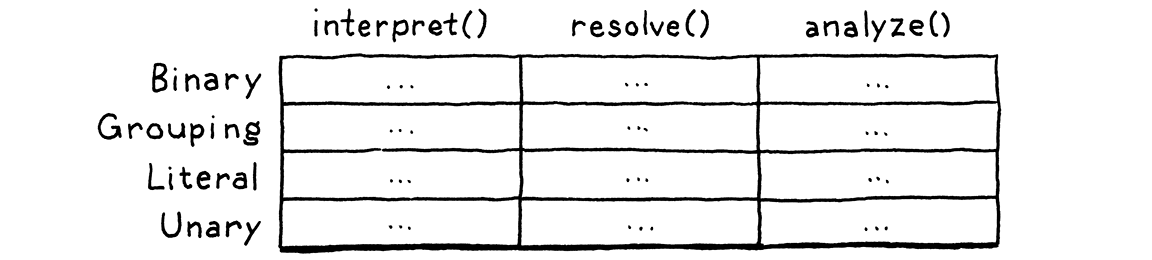{kind=link}

面向对象编程可以较好地解决新增行的问题,而函数式编程则可以较好地支持新增列(面向对象编程可以用visitor设计模式来模拟之)。 但是,目前并没有很好的办法来支持同时新增行和列。
在PyTorch中,本问题的表行索引为算子,列索引为DispatchKey (描述CPU/CUDA等设备后端,和Autograd/Tracing等PyTorch功能),表格单元则为KernelFunction(某个算子为某个DispatchKey提供的功能实现),如下图所示:
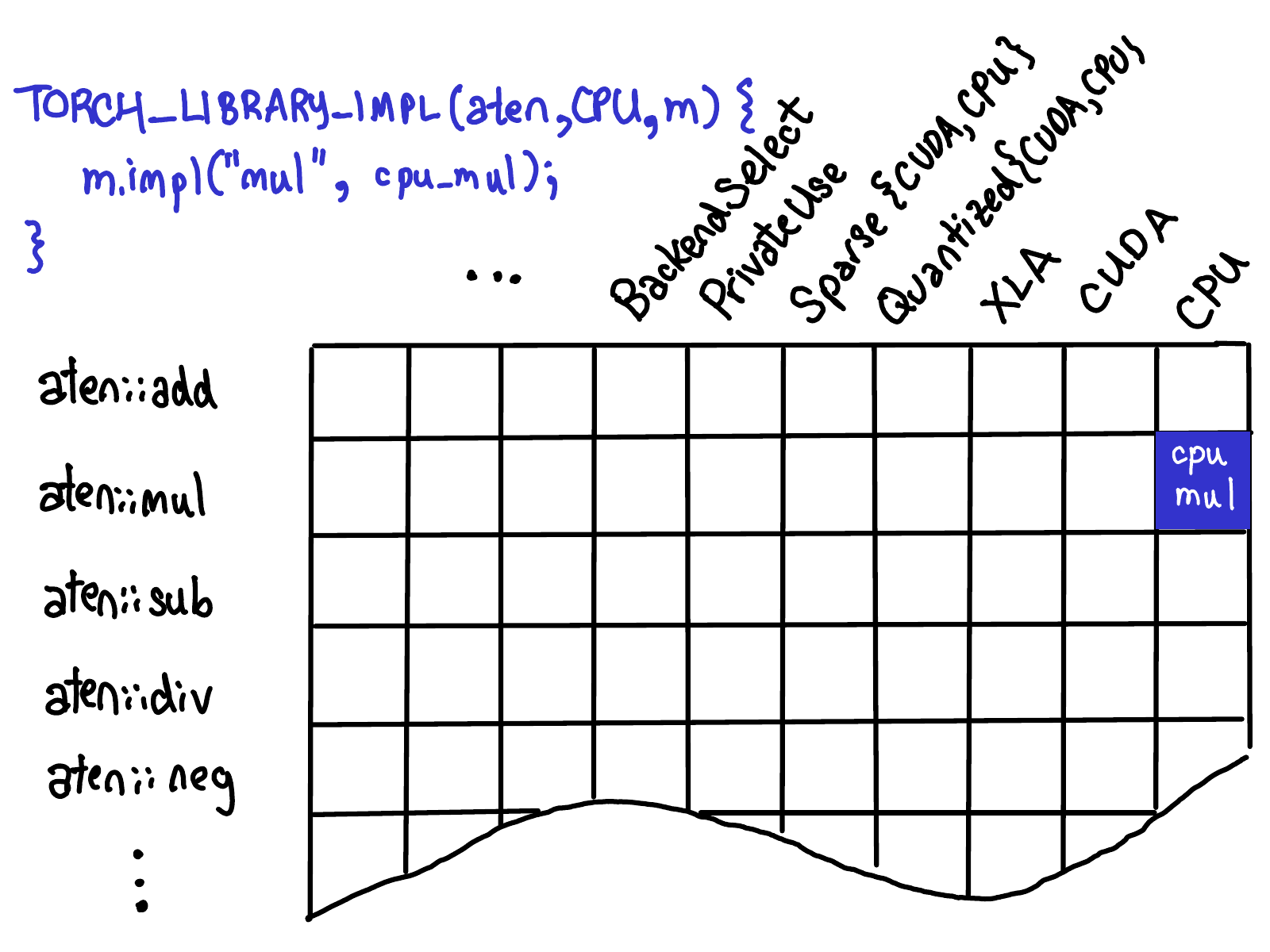{kind=link}

Dispatcher对本问题的解法如下:
- 首先,完全解耦合掉本问题的行(算子)和列(DispatchKey), 其基础管理单元为表中的单元格(KernelFunction)。
然后,通过一个控制中枢来管理表中的所有KernelFunction,并在运行时综合考虑算子入参和thread local变量等各个因素(用DispatchKey来描述)来选取出一个KernelFunction来执行,如下图所示:

“综合考虑各种因素后再选取一个KernelFunction”本质上还解决了另外一个叫做multiple dispatch的问题。 C++虚函数仅支持single-dispatch, 因此用C++解决本问题时需要使用一些技巧,具体可以参考More Effective C++ Item 31: Making functions virtual with respect to more than one object. 除了上述的根据DispatchKey来dispatch外,KernelFunction内部还可能会根据tensor dtype来进一步dispatch, 其实现为简单的switch语句,本文将不讨论之。
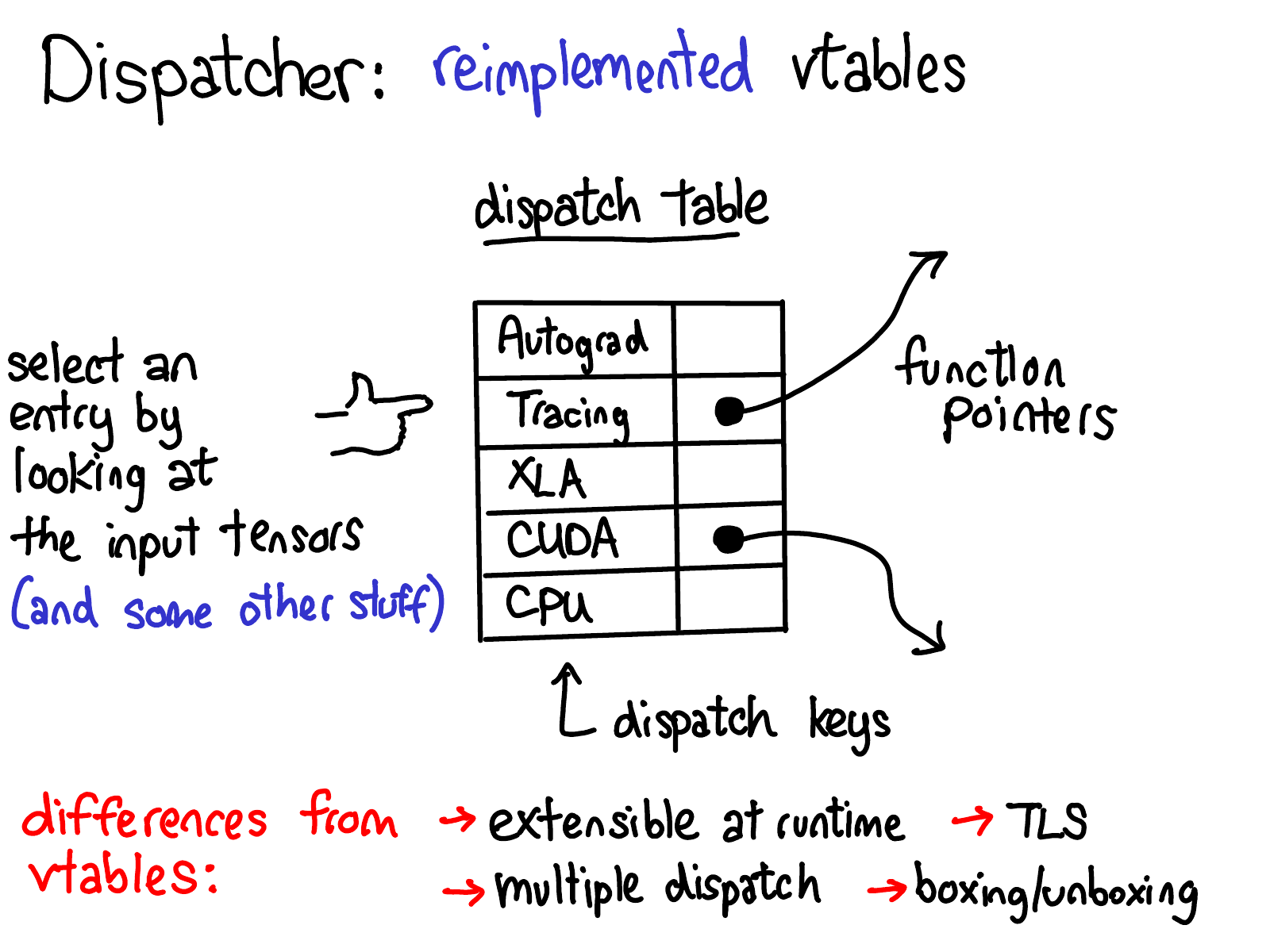{kind=link}
因此,dispatcher实现的关键在于如何描述上述KernelFucntion表,以及如何描述和综合被用于选取表中KernelFunction的因素(DispatchKey),下一小节将根据源码来分析其具体实现。
2. 源码分析
2.1. DispatchKey和DispatchKeySet
对于某个算子,其不止要适配CPU/CUDA/FPGA等设备后端,还需要适配Autograd/Tracing等PyTorch功能。 此外,Autograd等PyTorch功能需要对CPU/CUDA等可功能定制后端进行适配。 例如,Autograd的设备后端定制版包括AutogradCPU/AutogradCUDA/AutogradHIP等。
DispatchKey的功能为表达这些KernelFunction选取因素,而DispatchKeySet的功能则为综合多个DispatchKey并根据合成结果计算出KernelFunction表的列索引,下面将对两者进行详解。
2.1.1. DispatchKey
Dispatcher使用DispatchKey来表达这些KernelFunction选取因素的,其在实现上是一个uint16t枚举类,每一个KernelFunction选取因子都对于一个枚举项,如下:
enum class DispatchKey : uint16_t { // ~~~~~~~~~~~~~~~~~~~~~~~~~~ UNDEFINED ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ // Undefined = 0, CatchAll = Undefined, // ~~~~~~~~~~~~~~~~~~~~~~~~~~ Functionality Keys ~~~~~~~~~~~~~~~~~~~~~~ // Dense, FPGA, ... EndOfFunctionalityKeys, // End of functionality keys. // ~~~~~~~~~~~~~~ "Dense" Per-Backend Dispatch keys ~~~~~~~~~~~~~~~~~~~~ // #define DEFINE_PER_BACKEND_KEYS_FOR_BACKEND(n, prefix) prefix##n, #define DEFINE_PER_BACKEND_KEYS(fullname, prefix) \ StartOf##fullname##Backends, \ C10_FORALL_BACKEND_COMPONENTS( \ DEFINE_PER_BACKEND_KEYS_FOR_BACKEND, prefix) \ EndOf##fullname##Backends = prefix##Meta, C10_FORALL_FUNCTIONALITY_KEYS(DEFINE_PER_BACKEND_KEYS) #undef DEFINE_PER_BACKEND_KEYS #undef DEFINE_PER_BACKEND_KEYS_FOR_BACKEND EndOfRuntimeBackendKeys = EndOfAutogradFunctionalityBackends, // ~~~~~~~~~~~~~~~~~~~~~~ Alias Dispatch Keys ~~~~~~~~~~~~~~~~~~~~~~~~~~ // // Alias dispatch keys are synthetic dispatch keys which map to multiple runtime dispatch keys. Autograd, CompositeImplicitAutograd, ... StartOfAliasKeys = Autograd, EndOfAliasKeys = CompositeExplicitAutogradNonFunctional, // ~~~~~~~~~~~~~~~~~~~~~~~~~ BC ALIASES ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ // // The aliases exist for backwards compatibility reasons, they shouldn't be used CPUTensorId = CPU, CUDATensorId = CUDA, DefaultBackend = CompositeExplicitAutograd, PrivateUse1_PreAutograd = AutogradPrivateUse1, PrivateUse2_PreAutograd = AutogradPrivateUse2, PrivateUse3_PreAutograd = AutogradPrivateUse3, Autocast = AutocastCUDA, };
可以看出,DispatchKey可以分为Functionality / Per-Backend / Alias / BC (backwards compatibility)这几类。
另外,为了可维护性,代码使用C10_FORALL_FUNCTIONALITY_KEYS(DEFINE_PER_BACKEND_KEYS)宏来生成Autograd等PyTorch功能对设备后端适配的结果对应的DispatchKey枚举项。
2.1.2. DispatchKeySet
DispatchKeySet的功能为综合多个DispatchKey (实现了multiple-dispatch), 并根据合成结果计算出KernelFunction表的列索引。 DispatchKey自身无法较好地完成这些任务,原因如下:
- Alias和Per-Backend Functionality等DispatchKey枚举项不会对应到KernelFunction表的列索引。
- Per-Backend DispatchKey枚举项之间的信息具有冗余(比如AutogradCPU和AutogradCUDA都对应Autograd),因此在融合这些枚举项前需要拆分出其functionality和backend信息。
DispatchKeySet可以从DispathKey中提取出functionality和backend信息,因此多个DispatchKeySet之间可以之间使用位运算来融合。 DispatchKeySet用一个uint64t数据成员存储提取处理来的functionality和backend信息,如下图所示:
 在dispatcher选取KernelFunction时,functionality和backend之间是有优先级的,DispatchKeySet在高bit位存储具有高优先级的functionality和backend,如上图所示。
在dispatcher选取KernelFunction时,functionality和backend之间是有优先级的,DispatchKeySet在高bit位存储具有高优先级的functionality和backend,如上图所示。
DispatchKey与DispatchKeySet bit位以及KernelFunction表列索引之间的关系如下:
| DispatchKey类型 | 是否为一种DispatchKeySet bit位 | 是否对应一个KernelFunction表列索引 |
| 可定制的backend (BackendComponent中所有DispatchKey) | 是 | 否 |
| Per-Backend Functionality DispatchKey自身 | 是 | 否 |
| Per-Backend Functionality DispatchKey定制实例 | 否(但可以转化为两个bit为1的DispatchKeySet) | 是 |
| 不可自定义的后端 | 是 | 是 |
| 不可自定义的功能 | 是 | 是 |
DispatchKeySet的代码实现如下:
// A representation of a set of DispatchKeys. A DispatchKeySet contains both "functionality" bits and "backend bits", and every tensor holds its own DispatchKeySet. class DispatchKeySet final { public: // 从DispatchKey中提取functionality和backend信息 constexpr explicit DispatchKeySet(DispatchKey k) { ... } // 融合多个DispatchKeySet以实现multiple-dispatch constexpr DispatchKeySet operator|(DispatchKeySet other) const { return DispatchKeySet(repr_ | other.repr_); } // 计算DispatchKeySet对应的KernelFunction表列索引 int getDispatchTableIndexForDispatchKeySet() const { auto functionality_idx = DispatchKeySet(repr_ >> num_backends).indexOfHighestBit(); auto offset_and_mask = offsetsAndMasks()[functionality_idx]; auto backend_idx = DispatchKeySet((repr_ & offset_and_mask.mask) >> 1).indexOfHighestBit(); return offset_and_mask.offset + backend_idx; } private: constexpr DispatchKeySet(uint64_t repr) : repr_(repr) {} uint64_t repr_ = 0; };
其中,DispatchKeySet(DispatchKey k)构造函数被用于从DispatchKey中提取functionality和backend信息,而operator|(DispatchKeySet other)等运算符重载函数则被用于融合多个DispatchKeySet.
DispatchKeySet的最终目的是计算KernelFunction表列索引,其由getDispatchTableIndexForDispatchKeySet()来实现。
在本人极简编译的PyTorch v2.7.1版中,KernelFunction表一共有132列。
getDispatchTableIndexForDispatchKeySet()依赖的offsetsAndMasks()数组的计算方法如下:
std::array<FunctionalityOffsetAndMask, num_functionality_keys> initializeFunctionalityOffsetsAndMasks() { std::array<FunctionalityOffsetAndMask, num_functionality_keys> offsets_and_masks; // manually set the first entry, which corresponds to Undefined. offsets_and_masks[0] = FunctionalityOffsetAndMask(0, 0); // loop through every functionality key (aside from Undefined). for (const auto functionality_idx : c10::irange(1, num_functionality_keys)) { // functionality_idx should be Dense -> 1, ... auto prev_offset_and_mask = offsets_and_masks[functionality_idx - 1]; auto k = static_cast<DispatchKey>(functionality_idx); // If the previous functionality was not per-backend, then we can just // increment the previous offset. Otherwise, the next offset = // previous_offset + num_backends. auto next_offset = prev_offset_and_mask.offset + (prev_offset_and_mask.mask == 0 ? 1 : num_backends); // the mask is used in the runtime index calculation to find the offset of // the backend. For non-per-backend functionalities, this offset should // always be 0. Otherwise, we need to get the index of the backend (which we // can do using a backend mask). auto next_mask = isPerBackendFunctionalityKey(k) ? full_backend_mask : 0; offsets_and_masks[functionality_idx] = FunctionalityOffsetAndMask(next_offset, next_mask); } return offsets_and_masks; }
再结合结getDispatchTableIndexForDispatchKeySet()代码可以看出,一个普通functionality对应KernelFunction表一列,而一个per-backend functionality则对应numbackends列。
2.2. KernelFunction表与算子注册
2.2.1. KernelFunction表相关数据结构
KernelFunction表是一个二维表,行索引为算子,列索引为DispatchKey. PyTorth将KernelFunction表存储于Dispatcher::operators和Dispatcher::operatorLookupTable中,如下:
class TORCH_API Dispatcher final { private: std::list<OperatorDef> operators_; LeftRight<ska::flat_hash_map<OperatorName, OperatorHandle>> operatorLookupTable_; };
其中,operators中的OperatorDef存储了每个算子对应所有KernelFunction, operatorLookupTable表则将可以根据算子名查找到OperatorHandle, 而OperatorHandle本质上是指向OperatorDef的handle, 其定义如下:
class TORCH_API OperatorHandle { private: Dispatcher::OperatorDef* operatorDef_; std::list<Dispatcher::OperatorDef>::iterator operatorIterator_; };
OperatorDef的定义如下:
struct OperatorDef final { explicit OperatorDef(OperatorName&& op_name) : op(std::move(op_name)) {} impl::OperatorEntry op; size_t def_count = 0; size_t def_and_impl_count = 0; };
从中可以看出,OperatorDef的主要功能是给OperatorEntry提供引用计数,而OperatorEntry才是真正的实体, 其定义如下:
class TORCH_API OperatorEntry final { private: OperatorName name_; std::optional<AnnotatedSchema> schema_; std::array<KernelFunction, c10::num_runtime_entries> dispatchTable_; DispatchKeyExtractor dispatchKeyExtractor_; ska::flat_hash_map< DispatchKey, #ifdef C10_DISPATCHER_ONE_KERNEL_PER_DISPATCH_KEY // On mobile, we needn't worry about Jupyter notebooks. std::array<AnnotatedKernel, 1> #else std::list<AnnotatedKernel> #endif > kernels_; };
其中,dispatchTable数组存储了一个算子对应的所有KernelFunction (某个DispatchKey对应的数组索引可以使用根据DispatchKeySet::getDispatchTableIndexForDispatchKeySet()来计算), 而dispatchKeyExtractor则是算子专有的DispatchKey提取器(每个算子的DispatchKey提取规则各不相同),而kernels_ map则被用于记录当前算子为每一个DispatchKey注册过的KernelFunction (一个DispatchKey可以被注册多个KernelFunction, 但仅最新注册的有效)。
2.2.2. 算子注册
PyTorch算子注册方式包括TORCHLIBRARY API和RegisterOperators两种,官方更推荐TORCHLIBRARY API, 两者最终都通过调用Dispatcher::registerDef()和Dispatcher::registerImpl()来实现。
Dispatcher::registerDef()的功能为注册算子定义,其代码实现如下:
RegistrationHandleRAII Dispatcher::registerDef(FunctionSchema schema, std::string debug, std::vector<at::Tag> tags) { ... OperatorName op_name = schema.operator_name(); auto op = findOrRegisterName_(op_name); ... } OperatorHandle Dispatcher::findOrRegisterName_(const OperatorName& op_name) { ... operators_.emplace_back(OperatorName(op_name)); OperatorHandle handle(--operators_.end()); operatorLookupTable_.write([&] (ska::flat_hash_map<OperatorName, OperatorHandle>& operatorLookupTable) { operatorLookupTable.emplace(op_name, handle); }); return handle; }
可以看出,其主要功能为给在Dispatcher::operators_ list中新增一项OperatorDef, 同时还更新了算子查找表operatorLookupTable_.
Dispatcyher::registerImpl()的功能为给算子注册KernelFunction实现,其代码实现如下:
RegistrationHandleRAII Dispatcher::registerImpl( OperatorName op_name, std::optional<DispatchKey> dispatch_key, KernelFunction kernel, std::optional<impl::CppSignature> cpp_signature, std::unique_ptr<FunctionSchema> inferred_function_schema, std::string debug ) { ... auto handle = op.operatorDef_->op.registerKernel( *this, dispatch_key, std::move(kernel), std::move(cpp_signature), std::move(inferred_function_schema), std::move(debug) ); ... }
可以看出,其主要通过调用OperatorEntry::registerKernel()来注册KernelFunction, 其实现如下:
OperatorEntry::AnnotatedKernelContainerIterator OperatorEntry::registerKernel( const c10::Dispatcher& dispatcher, std::optional<DispatchKey> dispatch_key, KernelFunction kernel, std::optional<CppSignature> cpp_signature, std::unique_ptr<FunctionSchema> inferred_function_schema, std::string debug ) { ... auto& k = dispatch_key.has_value() ? kernels_[*dispatch_key] : kernels_[DispatchKey::CompositeImplicitAutograd]; #ifdef C10_DISPATCHER_ONE_KERNEL_PER_DISPATCH_KEY k[0].kernel = std::move(kernel); k[0].inferred_function_schema = std::move(inferred_function_schema); k[0].debug = std::move(debug); #else k.emplace_front(std::move(kernel), std::move(inferred_function_schema), std::move(debug)); #endif AnnotatedKernelContainerIterator inserted = k.begin(); // update the dispatch table, i.e. re-establish the invariant // that the dispatch table points to the newest kernel if (dispatch_key.has_value()) { updateDispatchTable_(dispatcher, *dispatch_key); } else { updateDispatchTableFull_(dispatcher); } return inserted; }
从中可以看出,其先在OperatorEntry::kernels_ map中DispatchKey的对应列表中插入一项AnnotatedKernel, 然后再调用OperatorEntry::updateDispatchTable_()来更新OperatorEntry::dispatchTable_, 如下:
void OperatorEntry::updateDispatchTable_(const c10::Dispatcher& dispatcher, DispatchKey dispatch_key) { ... for (auto k : c10::getRuntimeDispatchKeySet(dispatch_key)) { updateDispatchTableEntry_(dispatcher, k); } ... } void OperatorEntry::updateDispatchTableEntry_(const c10::Dispatcher& dispatcher, DispatchKey dispatch_key) { const auto dispatch_ix = getDispatchTableIndexForDispatchKey(dispatch_key); if (C10_UNLIKELY(dispatch_ix == -1)) { return; } dispatchTable_[dispatch_ix] = computeDispatchTableEntry(dispatcher, dispatch_key); dispatchKeyExtractor_.setOperatorHasFallthroughForKey(dispatch_key, dispatchTable_[dispatch_ix].isFallthrough()); }
综上所述,注册算子定义的主要工作为在Dispatcher::operators_ list中新增一项OperatorDef, 而注册算子KernelFunction实现的主要工作为给该OperatorDef的OperatorEntry::kernels_ map中相应value列表中插入一个AnnotatedKernel后再更新OperatorEntry::dispatchTable_。
2.3. 运行时链路
PyTorch算子在执行时首先会根据算子名和schema等元数据(KernelFunction表行索引)在Dispatcher::dispatchTable_查找OperatorHandle, 然后再根据各处DispatchKey来计算DispatchKeySet以最终得到KernelFunction表列索引,最后使用该列索引在OperatorHandle对应的OperatorEntry中找到KernelFunction并调用之。
需要注意的时,KernelFunction内的逻辑可能会重复上述流程以执行该算子的其它KernelFunction。
例如,算子可能会先执行autograd相关逻辑,然后再执行算子对应的数学计算KernelFunction,而这些逻辑对应于多个不同的KernelFunction, 但它们都具有相同的执行流程。
接下来本节将以Tensor.add()为例分析Dispatcher运行时链路,其调用栈整体如下图所示:

当使用PyTorch Python前端执行tensor1 + tensor2后,经过pybind后将调用到C++侧THPVariableadd(), 如下:
static PyObject * THPVariable_add(PyObject* self_, PyObject* args, PyObject* kwargs) { ... auto dispatch_add = [](const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) -> at::Tensor { pybind11::gil_scoped_release no_gil; return self.add(other, alpha); }; ... }
之后将执行at::Tensor::add(), 如下:
inline at::Tensor Tensor::add(const at::Tensor & other, const at::Scalar & alpha) const { return at::_ops::add_Tensor::call(const_cast<Tensor&>(*this), other, alpha); } at::Tensor add_Tensor::call(const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) { static auto op = create_add_Tensor_typed_handle(); return op.call(self, other, alpha); }
at::Tensor::add()之间透穿调用到addTensor::call(), 其会先查找add算子对应的OperatorHandle, 然后再执行查找结果call()方法。
2.3.1. 查找OperatorHandle
createaddTensortypedhandle()的实现如下:
static C10_NOINLINE c10::TypedOperatorHandle<add_Tensor::schema> create_add_Tensor_typed_handle() { return c10::Dispatcher::singleton() .findSchemaOrThrow(add_Tensor::name, add_Tensor::overload_name) .typed<add_Tensor::schema>(); }
可以看出,其本质上调用Dispatcher::findSchemaOrThrow()来完成任务,如下:
OperatorHandle Dispatcher::findSchemaOrThrow(const char* name, const char* overload_name) { auto it = findSchema({name, overload_name}); ... return it.value(); } std::optional<OperatorHandle> Dispatcher::findSchema(const OperatorName& overload_name) { auto it = findOp(overload_name); .. }
可以看出,findSchemaOrThrow()最终将调用到findOp(), 如下:
std::optional<OperatorHandle> Dispatcher::findOp(const OperatorName& overload_name) { return operatorLookupTable_.read([&] (const ska::flat_hash_map<OperatorName, OperatorHandle>& operatorLookupTable) -> std::optional<OperatorHandle> { auto found = operatorLookupTable.find(overload_name); if (found == operatorLookupTable.end()) { return std::nullopt; } return found->second; }); }
findOp()本质上是在根据OperatorName来查前述Dispatcher::operatorLookupTable_ map. 对于add算子,最终查找结果为OperatorHandle的子类TypedOperatorHandle.
2.3.2. 执行OperatorHandle
addTensor::call()在查找到OperatorHandle后,会执行TypedOperatorHandle::call()方法,如下:
template <class Return, class... Args> class TypedOperatorHandle<Return(Args...)> final : public OperatorHandle { public: C10_ALWAYS_INLINE Return call(Args... args) const { return c10::Dispatcher::singleton().call<Return, Args...>( ,*this, std::forward<Args>(args)...); } };
可以看出,其通过调用Dispatcher::call()来完成任务,如下:
template <class Return, class... Args> C10_ALWAYS_INLINE_UNLESS_MOBILE Return Dispatcher::call( const TypedOperatorHandle<Return(Args...)>& op, Args... args) const { auto dispatchKeySet = op.operatorDef_->op.dispatchKeyExtractor() .template getDispatchKeySetUnboxed<Args...>(args...); ... const KernelFunction& kernel = op.operatorDef_->op.lookup(dispatchKeySet); ... return kernel.template call<Return, Args...>(op, dispatchKeySet, std::forward<Args>(args)...); }
call()首先会计算DispatchKeySet, 然后再根据DispatchKeySet计算出KernelFunction表列索引,之后再根据列索引从OperatorEntry中查找出KernelFunction, 最后再执行之。
除了Dispatcher::call()外,Dispatcher还有redispatch(), 其本质上和call()相同,只是其从入参获取DispatchKeySet, 而不是根据入参等来计算之,如下:
template <class Return, class... Args> inline Return Dispatcher::redispatch( const TypedOperatorHandle<Return(Args...)>& op, DispatchKeySet currentDispatchKeySet, Args... args) const { ... const KernelFunction& kernel = op.operatorDef_->op.lookup(currentDispatchKeySet); return kernel.template call<Return, Args...>( op, currentDispatchKeySet, std::forward<Args>(args)...); }
2.3.3. 计算DispatchKeySet
Dispatcher::call()会使用OperatorEntry::dispatchKeyExtractor来根据入参tensor/thread local变量/DispatchKeyExtractor中的算子自定义逻辑来综合计算出DispatchKeySet (实现来multiple-dispatch),如下:
template <class... Args> DispatchKeySet DispatchKeyExtractor::getDispatchKeySetUnboxed() const { auto ks = detail::multi_dispatch_key_set(args...); // Keys that are fallthrough should be skipped if (requiresBitsetPerBackend_) { c10::impl::LocalDispatchKeySet tls = c10::impl::tls_local_dispatch_key_set(); auto backend_idx = ((ks | tls.included_) - tls.excluded_).getBackendIndex(); return impl::computeDispatchKeySet( ks, nonFallthroughKeysPerBackend_[backend_idx]); } else { return impl::computeDispatchKeySet(ks, nonFallthroughKeys_); } }
可以看出,getDispatchKeySetUnboxed()首先会利用detail::multidispatchkeyset(args…)来从融合入参中的DispatchKey, 然后融合LocalDispatchKeySet, 最后再融合DispatchKeyExtractor的算子自定义nonFallthroughKeys_. multidispatchkeyset()的计算逻辑如下:
template <typename... Args> DispatchKeySet multi_dispatch_key_set(const Args&... args) { return MultiDispatchKeySet().apply(args...).ts; } struct MultiDispatchKeySet : at::IterArgs<MultiDispatchKeySet> { DispatchKeySet ts; void operator()(const at::Tensor& x) { ts = ts | x.key_set(); } }; struct C10_API TensorImpl : public c10::intrusive_ptr_target { private: DispatchKeySet key_set_; };
可以看出,multidispatchkeyset()本质上为对所有入参tensor对象的keyset做位或运算。 computeDispatchKeySet()的计算逻辑如下:
inline DispatchKeySet computeDispatchKeySet( DispatchKeySet ks, DispatchKeySet key_mask) { c10::impl::LocalDispatchKeySet local = c10::impl::tls_local_dispatch_key_set(); return (((ks | local.included_) - local.excluded_) & key_mask); }
除了DispatchKeyExtractor::getDispatchKeySetUnboxed()外,DispatchKeyExtractor还有getDispatchKeySetBoxed(), 其本质上和getDispatchKeySetUnboxed()相同,只是其是从JIT stack中获取入参tensor,如下:
DispatchKeySet DispatchKeyExtractor::getDispatchKeySetBoxed(const torch::jit::Stack* stack) const { DispatchKeySet ks; dispatch_arg_indices_reverse_.for_each_set_bit([&](size_t reverse_arg_index) { const auto& ivalue = torch::jit::peek(*stack, 0, reverse_arg_index + 1); ... }
2.3.4. 查找KernelFunction
在得到DispatchKeySet后,OperatorEntry::lookup()先通过DispatchKeySet::getDispatchTableIndexForDispatchKeySet()来计算出其对应的KernelFunction表列索引,然后再直接查dispatchTable数组以获得KernelFunction, 如下:
const KernelFunction& OperatorEntry::lookup(DispatchKeySet ks) const { const auto idx = ks.getDispatchTableIndexForDispatchKeySet(); if (C10_UNLIKELY(idx == -1)) { reportError(ks.highestPriorityTypeId()); } const auto& kernel = dispatchTable_[idx]; ... return kernel; }
2.3.5. 调用KernelFunction
在得到KernelFunction后,Dispatcher将执行KernelFunction::call(), 其逻辑如下:
template <class Return, class... Args> C10_ALWAYS_INLINE Return KernelFunction::call( const OperatorHandle& opHandle, DispatchKeySet dispatchKeySet, Args... args) const { ... auto* functor = boxed_kernel_func_.getFunctor(); return callUnboxedKernelFunction<Return, Args...>( unboxed_kernel_func_, functor, dispatchKeySet, std::forward<Args>(args)...); ... }
可以看出,其将通过调用callUnboxedKernelFunction()来完成任务,如下:
template <class Return, class... Args> inline Return callUnboxedKernelFunction( void* unboxed_kernel_func, OperatorKernel* functor, DispatchKeySet dispatchKeySet, Args&&... args) { using ActualSignature = Return(OperatorKernel*, DispatchKeySet, Args...); ActualSignature* func = reinterpret_cast<ActualSignature*>(unboxed_kernel_func); return (*func)(functor, dispatchKeySet, std::forward<Args>(args)...); } template <class KernelFunctor, class ReturnType, class... ParameterTypes> struct wrap_kernel_functor_unboxed_< KernelFunctor, ReturnType(DispatchKeySet, ParameterTypes...)> final { static ReturnType call( OperatorKernel* functor, DispatchKeySet dispatchKeySet, ParameterTypes... args) { KernelFunctor* functor_ = static_cast<KernelFunctor*>(functor); return (*functor_)(dispatchKeySet, std::forward<ParameterTypes>(args)...); } }; template <class FuncPtr, class ReturnType, class... Parameters> class WrapFunctionIntoFunctor_< FuncPtr, ReturnType, guts::typelist::typelist<Parameters...>> final : public c10::OperatorKernel { public: C10_ALWAYS_INLINE decltype(auto) operator()(Parameters... args) { return (*FuncPtr::func_ptr())(std::forward<Parameters>(args)...); } };
可以看出,callUnboxedKernelFunction()在调用到KerneFunction的最终目标前经过来多次完美转发。
对于tensor1 + tensor2, add算子第一次执行的KernelFunction最终将执行torch::autograd::unamed::VariableType::add_Tensor().
2.3.6. redispatch
torch::autograd::unamed::VariableType::add_Tensor()的实现如下,
at::Tensor torch::autograd::unamed::VariableType::add_Tensor(c10::DispatchKeySet ks, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) { ... auto _tmp = ([&]() { at::AutoDispatchBelowADInplaceOrView guard; return at::redispatch::add(ks & c10::after_autograd_keyset, self_, other_, alpha); })(); ... }
可以看出,其首先使用at::AutoDispatchBelowADInplaceOrView guard;屏蔽掉autograd相关DispatchKeySet, 这可以使得后面Dispatcher流程最终查询到add算子的其它KernelFunction.
然后,其将执行at::redispatch::add(), 如下:
inline at::Tensor at::redispatch::add(c10::DispatchKeySet dispatchKeySet, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha=1) { return at::_ops::add_Tensor::redispatch(dispatchKeySet, self, other, alpha); } at::Tensor add_Tensor::redispatch(c10::DispatchKeySet dispatchKeySet, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) { static auto op = create_add_Tensor_typed_handle(); return op.redispatch(dispatchKeySet, self, other, alpha); } C10_ALWAYS_INLINE Return redispatch(DispatchKeySet currentDispatchKeySet, Args... args) const { return c10::Dispatcher::singleton().redispatch<Return, Args...>( *this, currentDispatchKeySet, std::forward<Args>(args)...); }
最终,将执行到前面的介绍过的Dispatcher::redispatch(), 后面的执行逻辑和前面描述过流程大同小异,因此本节源码分析至此而止。